
A/B Testing in Data Science: A 2026 Practitioner's Guide
TL;DR:
- A/B testing in data science involves randomized experiments comparing two variables to identify which improves a specific metric. Proper hypothesis formulation, sample size calculation, and choosing the right statistical framework are essential for reliable results and ongoing optimization. Advanced methods like CUPED and Bayesian analysis enhance test sensitivity, enabling faster, more accurate decision-making at scale.
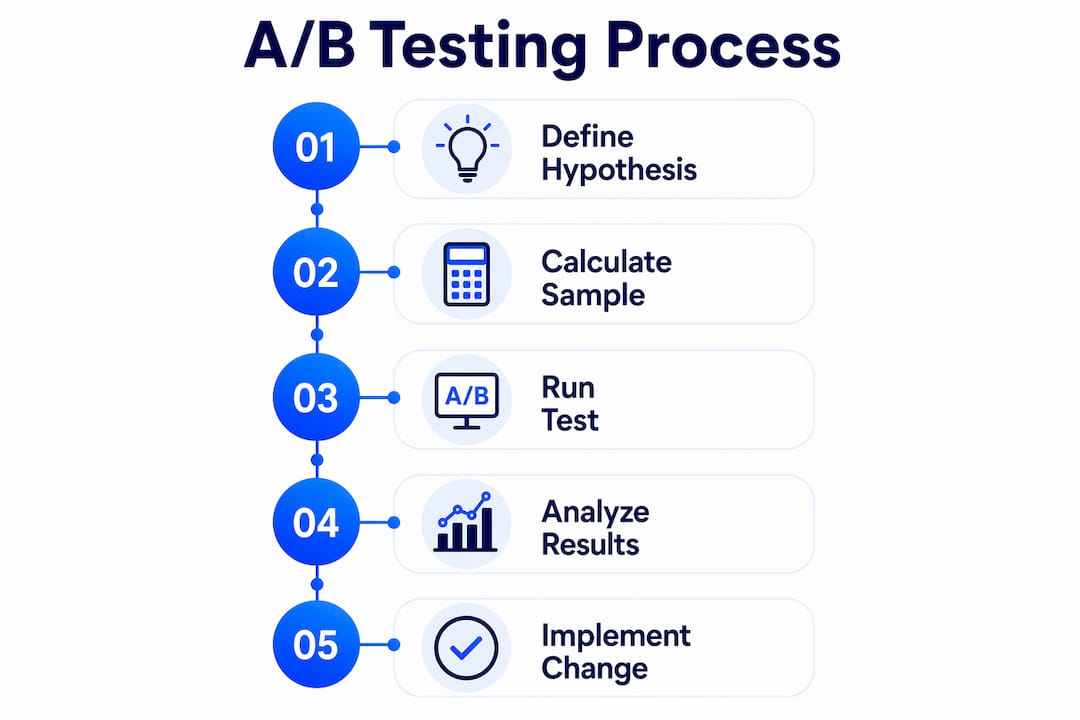
A/B testing in data science is a controlled, randomized experiment that compares two versions of a variable to determine which produces a statistically superior outcome on a defined conversion metric. Known formally as a randomized controlled trial (RCT) in research contexts, the method is the backbone of data-driven decision making for marketing teams and product analysts alike. When you change a landing page headline, a call-to-action button color, or an email subject line, an A/B test tells you whether that change actually moves the needle or just feels like it does. The difference between intuition and evidence is exactly where data science earns its value.
What is A/B testing in data science and how does it work?
A/B testing, also called split testing, divides your audience randomly into two groups: one sees the control (version A) and the other sees the variant (version B). You measure a primary metric, such as conversion rate, click-through rate, or revenue per visitor, and use statistical analysis to determine whether any observed difference is real or due to chance. The core principle is randomization. Without it, you cannot isolate the effect of your change from confounding variables like day of week, traffic source, or device type.
Strong hypotheses are structured with four components: a description of the problem backed by data, the proposed change, the expected outcome, and the metric you will use to measure it. A weak hypothesis says "let's try a red button." A strong one says "our heatmap data shows 40% of users ignore the current gray CTA; changing it to high-contrast orange is expected to increase click-through rate by 10%, measured over 14 days." That specificity is what separates rigorous experimentation from cargo-cult testing.
Selecting the right primary metric matters more than most analysts realize. You want one metric that directly reflects your business goal, plus two or three guardrail metrics. Guardrail metrics such as page load time and support ticket volume protect you from a scenario where your variant improves conversions but quietly degrades user experience elsewhere. Tracking both keeps your wins honest.
How to calculate sample size before you start
Sample size calculation is where most marketing A/B tests fail before they even launch. Standard A/B test configurations use a 95% confidence level (alpha = 0.05) and 80% statistical power (1-beta = 0.80). These thresholds balance the risk of false positives against your ability to detect real effects. Running an underpowered test with too few users wastes resources and risks missing a true improvement entirely.

The minimum detectable effect (MDE) drives your sample size calculation more than any other input. A smaller MDE requires a larger sample because you need more data to detect a subtle signal. If your current conversion rate is 3% and you want to detect a 0.5 percentage point lift, you will need far more traffic than if you are looking for a 1.5 point lift. Tools like Evan Miller's sample size calculator or the built-in power analysis in Python's "statsmodels` library make this calculation straightforward.
Pro Tip: Set your MDE based on the minimum business-relevant improvement, not the largest effect you hope to see. Optimistic MDEs produce underpowered tests that generate false negatives.
Frequentist vs. Bayesian: which statistical approach fits your test?
The two dominant statistical frameworks for A/B testing data science are frequentist and Bayesian. Most analysts learn frequentist methods first, but Bayesian approaches are gaining ground fast in industry practice, particularly at companies where stakeholder communication matters as much as statistical rigor.
The frequentist approach uses p-values and confidence intervals. You set a fixed sample size before the test, run it to completion, and then check whether the p-value falls below your alpha threshold. If p < 0.05, you reject the null hypothesis. The limitation is that this framework answers a question most stakeholders do not actually ask. A p-value tells you the probability of observing your data if the null hypothesis were true. It does not tell you the probability that your variant is better.
Bayesian testing directly answers the question "what is the probability that B outperforms A?" and eliminates the false positive inflation caused by peeking at results mid-test. It also allows you to incorporate prior data, such as results from previous tests on similar pages, which makes early stopping decisions more defensible. Many data scientists note that Bayesian probability statements resonate better with stakeholders than p-values, which are frequently misunderstood even by experienced analysts.
| Characteristic | Frequentist | Bayesian |
|---|---|---|
| Primary output | p-value, confidence interval | Posterior probability P(B > A), credible interval |
| Sample size | Fixed in advance | Flexible, continuous monitoring allowed |
| Peeking penalty | Inflates false positives | No penalty with proper priors |
| Prior data use | Not incorporated | Explicitly incorporated |
| Stakeholder clarity | Often misinterpreted | Intuitive probability statements |
| Best for | High-traffic, fixed-duration tests | Iterative tests, low-traffic scenarios |
Netflix, Uber, and LinkedIn data scientists recommend advanced experimentation techniques including Bayesian frameworks and cluster randomization for production-level rigor. That endorsement from organizations running millions of concurrent experiments carries real weight.
Pro Tip: For a deeper breakdown of when to use each framework in marketing contexts, the Gostellar guide on Bayesian vs. frequentist methods is worth bookmarking.
Common pitfalls that corrupt A/B test results
Even well-designed tests fail when execution is sloppy. These are the errors that produce false confidence and bad decisions.
-
The peeking problem. Checking results before your test reaches its predetermined sample size inflates false positive rates above 25%. Every time you peek and consider stopping early, you are effectively running multiple hypothesis tests, each adding to your cumulative error rate. The fix is to pre-commit to a sample size and duration before launch, then leave the test alone.
-
Multiple comparisons without correction. Testing multiple metrics without statistical corrections inflates false discovery rates. If you test ten metrics simultaneously at alpha = 0.05, you expect at least one false positive by chance alone. Bonferroni correction and the Benjamini-Hochberg false discovery rate method both address this, with Benjamini-Hochberg being less conservative for exploratory analysis.
-
The novelty effect. Users behave differently when they encounter something new. A fresh design or new feature often generates a temporary spike in engagement that fades within days. Running tests for at least two full business cycles, typically 14 days minimum, smooths out these transient behaviors and gives you a stable signal.
-
Testing too many variables at once. Changing the headline, image, and CTA button simultaneously makes it impossible to know which element drove the result. Test one variable per experiment unless you are running a full factorial design with sufficient traffic to support it.
-
Ignoring segment heterogeneity. An overall null result can hide a strong positive effect in a specific user segment. Always analyze results by device type, traffic source, and user cohort before declaring a test inconclusive.
Pro Tip: Build a pre-test checklist that forces you to document your hypothesis, primary metric, sample size, and planned duration before any test goes live. The A/B testing checklist from Gostellar covers every step in a format you can reuse across campaigns.
Advanced techniques that improve test sensitivity
Standard A/B testing gets you far, but high-volume practitioners use several advanced methods to extract more signal from the same data.
-
CUPED (Controlled-experiment Using Pre-Experiment Data). This variance reduction technique uses pre-experiment data to control for user-level differences that exist before the test starts. CUPED reduces variance by 30 to 50%, increasing test sensitivity without requiring more traffic. Microsoft pioneered the method and it is now standard practice at most major tech firms.
-
Ego-cluster randomization. When users interact with each other, such as in social networks or marketplace platforms, standard individual randomization creates interference between groups. Cluster randomization assigns entire social clusters to the same variant, preserving the independence assumption that statistical tests require.
-
Sequential testing with alpha spending. Sequential testing frameworks allow you to monitor results continuously while controlling the overall false positive rate. Alpha spending functions, such as the O'Brien-Fleming boundary, allocate your error budget across multiple looks at the data. This is the statistically valid answer to the peeking problem, not a workaround.
-
Multi-armed bandit algorithms. Where traditional A/B testing splits traffic equally and waits for a winner, multi-armed bandit algorithms dynamically route more traffic to better-performing variants in real time. This approach optimizes the exploration-exploitation tradeoff and is particularly useful in high-velocity environments like email campaigns or paid ad creative testing where speed of learning matters more than statistical precision.
These methods are not theoretical. They are production tools used by data science teams at scale. If your organization runs more than a dozen tests per month, investing time in CUPED and sequential testing will pay off in faster, more reliable decisions.
How to interpret results and apply them to conversion optimization
Reading a test result correctly is a skill that separates analysts who drive business impact from those who generate reports. A statistically significant result means the observed difference is unlikely to be due to chance at your chosen confidence level. It does not mean the effect is large, permanent, or guaranteed to replicate.
-
Check practical significance alongside statistical significance. A 0.1% lift in conversion rate may be statistically significant with enough traffic but economically irrelevant. Always translate your result into revenue or business impact before recommending a rollout.
-
Run segment analysis on every test. Break results down by device, geography, new vs. returning users, and traffic source. A variant that underperforms overall may show a strong positive effect on mobile users, which is a finding worth acting on separately.
-
Document every test outcome, including losses. Failed tests contain as much information as winners. A variant that reduced conversion tells you something concrete about your users' preferences. Teams that document and share these learnings build institutional knowledge that compounds over time. Analytics-driven marketing delivers measurably better ROI precisely because it treats every experiment as a learning asset, not just a win-or-lose decision.
-
Connect results to your next hypothesis. A/B testing is iterative. Each result should inform the next test. If a long-form landing page beat a short one, your next test might explore which section of the long page drives the most engagement.
Pro Tip: For real-world examples of how high-impact tests translate into conversion gains, the Gostellar collection of A/B testing examples shows exactly how these principles play out across industries.
Key takeaways
Rigorous A/B testing in data science requires correct hypothesis structure, adequate sample size, the right statistical framework, and disciplined execution to produce results you can act on with confidence.
| Point | Details |
|---|---|
| Hypothesis structure | Build every hypothesis with a data-backed problem, proposed change, expected outcome, and measurement metric. |
| Sample size discipline | Calculate sample size using power analysis at alpha = 0.05 and power = 0.80 before launching any test. |
| Statistical framework choice | Use frequentist methods for fixed-duration, high-traffic tests; use Bayesian methods when continuous monitoring or stakeholder clarity matters. |
| Avoid peeking and multiple testing | Pre-commit to duration and apply Bonferroni or Benjamini-Hochberg corrections when tracking multiple metrics. |
| Advanced sensitivity methods | Apply CUPED or sequential testing when you need faster, more sensitive results without increasing traffic. |
Why most A/B testing programs plateau after the first few wins
I have reviewed dozens of A/B testing programs across marketing and product teams, and the pattern is consistent. The first three to five tests produce clear wins because the low-hanging fruit is real. A better headline, a cleaner CTA, a faster page. After that, teams hit a wall and start running tests that produce inconclusive results or marginal lifts. The instinct is to blame the tool or the traffic volume. The real problem is almost always the hypothesis quality.
Teams that sustain compounding gains treat hypothesis generation as a research process, not a brainstorming session. They pull from session recordings, user interviews, cohort analysis, and support ticket themes before writing a single test brief. The rigor that goes into the hypothesis determines the ceiling of what the test can teach you.
The other pattern I see consistently is a reluctance to adopt Bayesian methods because they feel unfamiliar. That reluctance is expensive. When you can show a stakeholder that "there is an 87% probability that variant B outperforms A," you get faster decisions and fewer requests to "just run it a bit longer." The communication advantage alone justifies the learning curve.
The future of A/B testing in data science belongs to teams that combine statistical rigor with a genuine learning culture. Sequential testing and multi-armed bandits will become standard, not advanced. The teams building those habits now will have a compounding advantage over those still running underpowered tests and peeking at dashboards.
— Juan
Run better experiments with Gostellar
If you are ready to move from theory to execution, Gostellar is built for exactly this workflow.
Gostellar's platform handles traffic splitting, real-time statistical reporting, and goal tracking without requiring engineering resources. The no-code visual editor lets you set up and launch tests in minutes, while the 5.4KB script keeps your page performance intact. Whether you are running your first conversion experiment or managing a full testing program across multiple campaigns, Gostellar gives you the data you need to make confident decisions. Start free for up to 25,000 monthly tracked users at Gostellar.
FAQ
What is A/B testing in data science?
A/B testing in data science is a randomized controlled experiment that compares two versions of a variable to determine which performs better on a defined metric. It uses statistical analysis to distinguish real effects from random variation.
How do you calculate sample size for an A/B test?
Sample size is calculated using power analysis, typically setting alpha at 0.05 and statistical power at 0.80, with the minimum detectable effect (MDE) as the key input. Smaller MDEs require larger sample sizes to detect reliably.
What is the peeking problem in A/B testing?
Peeking means checking results before the test reaches its planned sample size, which inflates false positive rates above 25%. The fix is to pre-commit to a sample size and duration, or use sequential testing frameworks that account for multiple looks.
When should you use Bayesian instead of frequentist A/B testing?
Bayesian testing is preferable when you need continuous monitoring, want to incorporate prior experiment data, or need to communicate results to non-technical stakeholders. It directly answers "what is the probability that B beats A?" without the misinterpretation risk of p-values.
What is CUPED and why does it matter?
CUPED is a variance reduction technique that uses pre-experiment user data to increase test sensitivity by 30 to 50%, allowing you to detect smaller effects with the same traffic volume. It is widely used by data science teams at Microsoft, Netflix, and similar organizations.
Recommended
Published: 6/5/2026