
Understanding Statistical Power: Essential Guide for Marketers 2025
Marketers often rely on A/B testing to figure out what really moves the needle, but there’s one factor that can quietly wreck your results without you ever noticing. A whopping 50 percent of marketing experiments may be missing true effects simply because their statistical power is too low. Sounds shocking, right? Here’s the twist. Focusing on bigger sample sizes or budget alone will not fix the problem—instead, understanding how statistical power actually works can be the difference between trusting your data and flushing your insights down the drain.
Table of Contents
- What Is Statistical Power And Why It Matters
- Key Factors That Influence Statistical Power
- How To Calculate And Improve Statistical Power In A/B Testing
- Common Mistakes And Best Practices For Marketers
Quick Summary
| Takeaway | Explanation |
|---|---|
| Statistical power is critical for reliable marketing experiments | It is the probability of detecting a genuine effect, helping marketers avoid false negatives and make informed decisions based on robust data. |
| Sample size significantly influences statistical power | Larger sample sizes improve the precision of estimates and reduce standard errors, enhancing the ability to detect true effects in experiments. |
| Balancing significance level is essential | Choosing an appropriate significance level (typically set at 0.05) impacts the likelihood of detecting true effects vs. experiencing false positives and should align with experimental goals. |
| Practical strategies can enhance statistical power | Marketers should reduce variability, increase sample sizes, focus on meaningful effect sizes, and use precise measurement tools to ensure reliable and actionable insights. |
| Avoid common statistical misconceptions | Distinguish between statistical significance and practical relevance, and understand that non-significant results do not imply no effect exists; proper interpretation is key to making data-informed decisions. |
What Is Statistical Power and Why It Matters
Marketers navigating complex data landscapes need a powerful tool to understand the reliability of their experimental results. Statistical power provides exactly that critical insight. At its core, statistical power represents the probability of detecting a genuine effect when it actually exists in your marketing experiments.
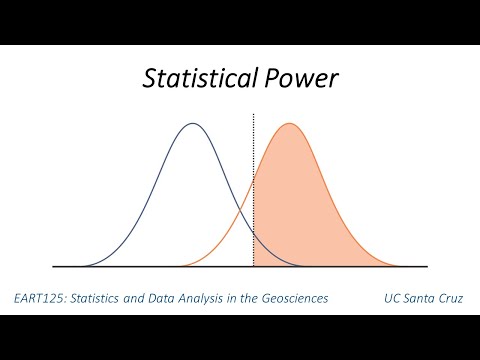

The Fundamental Concept of Statistical Power
Statistical power is not just a technical metric it is a crucial determinant of research and experimental reliability. According to research from the National Institutes of Health, statistical power is the probability that a statistical test will correctly reject a false null hypothesis. In marketing contexts, this translates to understanding whether your experimental results are genuine or merely coincidental.
Think of statistical power as a detective's ability to find evidence. A high statistical power means your detective skills are sharp you are more likely to uncover true marketing insights. Conversely, low statistical power suggests you might miss important patterns or trends that could significantly impact your marketing strategies.
Why Statistical Power Matters in Marketing Experiments
Reducing False Negatives: Research from UC Press emphasizes that adequate statistical power minimizes Type II errors false negatives where real effects are overlooked. For marketers, this means preventing missed opportunities that could drive substantial business growth.
Consider a conversion rate optimization experiment. Low statistical power might lead you to discard a potentially game changing landing page design simply because your sample size was insufficient. By understanding and implementing proper statistical power calculations, you protect your marketing investments from premature or incorrect conclusions.
Calculating and Improving Statistical Power
Improving statistical power involves several strategic approaches. Sample size directly influences your power larger samples provide more reliable results. Reducing measurement variability and increasing the expected effect size can also enhance statistical power.
Key factors influencing statistical power include:
- Sample Size: Larger samples increase detection probability
- Significance Level: Typically set at 0.05 in marketing research
- Effect Size: The magnitude of the difference you are trying to detect
Marketers should view statistical power as a critical quality control mechanism. It transforms raw data into actionable insights by ensuring that experimental results are not just random fluctuations but meaningful patterns that can drive strategic decision making.
By mastering statistical power, you move from guesswork to precision in your marketing experiments. You become equipped to make data driven decisions with confidence understanding not just what happened but the reliability of those observations.
Key Factors That Influence Statistical Power
Navigating the complex terrain of statistical analysis requires a deep understanding of the factors that can make or break your research insights. Statistical power is not a static concept but a dynamic measure influenced by multiple interconnected variables that marketers must carefully consider.
Sample Size and Its Critical Role
Research from Biochemia Medica highlights that sample size is perhaps the most pivotal factor in determining statistical power. Larger sample sizes reduce standard error and improve the precision of estimates, making it easier to detect true effects in your marketing experiments.
Think of sample size like a microscope. A small sample is like looking through a weak lens where details are blurry and indistinct. As you increase your sample size, the lens becomes more powerful revealing nuanced insights that were previously invisible. In marketing experiments, this means gathering more data points to ensure your conclusions are robust and representative.

Effect Size and Measurement Precision
According to statistical research, effect size represents the magnitude of the difference or relationship you are trying to detect. Larger effect sizes inherently increase statistical power because more substantial differences between groups are easier to identify.
For marketers, this translates to understanding the practical significance of your experimental results. A tiny improvement in conversion rates might be statistically significant but economically irrelevant. Conversely, a meaningful change that substantially impacts user behavior represents a powerful insight.
Significance Level and Error Management
Statistical analysis literature reveals that the chosen significance level (α) profoundly impacts statistical power. Typically set at 0.05, this threshold determines the balance between detecting true effects and avoiding false positives.
A lower significance level increases the stringency of your analysis but reduces the likelihood of detecting subtle effects. Conversely, a higher level makes it easier to find significant results but raises the risk of false discoveries. Marketers must strike a delicate balance choosing a significance level that matches their risk tolerance and experimental goals.
For those looking to dive deeper into experimental design challenges, learn more about A/B testing complexities to refine your statistical approach.
Key considerations for managing statistical power include:
- Precise Measurement: Reduce variability in your experimental setup
- Strategic Sampling: Collect representative and sufficient data
- Clear Hypothesis: Define expected effects before conducting experiments
By understanding these interconnected factors, marketers transform statistical power from an abstract concept into a practical tool for making confident, data driven decisions. Each experiment becomes an opportunity to uncover meaningful insights that can drive strategic marketing innovations.
Here is a table summarizing the key factors that influence statistical power in marketing experiments, making it easier to compare and understand their roles:
| Factor | Description | How It Impacts Power |
|---|---|---|
| Sample Size | Number of data points collected | Larger size increases power |
| Effect Size | Magnitude of difference being measured | Larger effect size increases power |
| Significance Level | Probability threshold for detecting an effect (commonly 0.05) | Higher threshold increases risk of false positives, lower threshold increases risk of false negatives |
| Measurement Precision | Accuracy and consistency of data collection | Higher precision increases power |
| Variability | Amount of noise or randomness in data | Lower variability increases power |
How to Calculate and Improve Statistical Power in A/B Testing
A/B testing is a powerful method for making data driven marketing decisions, but its effectiveness hinges on understanding and optimizing statistical power. Marketers must navigate a complex landscape of calculations and strategic considerations to ensure their experiments yield meaningful insights.
Determining Sample Size and Minimum Detectable Effect
Research from Genuine CRO emphasizes that sample size is the cornerstone of statistical power. The larger your sample, the more reliable your results become. Determining the right sample size involves carefully balancing multiple factors.
According to Codecademy's statistical research, the Minimum Detectable Effect (MDE) plays a crucial role. MDE represents the smallest meaningful difference your test aims to detect. Smaller MDEs require larger sample sizes, while larger MDEs can reduce sample size requirements but risk overlooking subtle yet important variations.
Significance Level and Power Calculation
Insights from Lomit Patel's research reveal standard practices in statistical testing. Typically, marketers set the significance level (alpha) at 0.05 and desired power at 0.8. This balance helps manage the risks of Type I and Type II errors while maintaining experimental reliability.
Power calculation involves several key steps:
- Determine your expected effect size
- Choose an appropriate significance level
- Calculate the required sample size
- Account for potential drop offs or incomplete data
For marketers seeking deeper insights into experimental design nuances, explore advanced A/B testing strategies to refine your approach.
Practical Strategies for Improving Statistical Power
Improving statistical power is not just about mathematical calculations. Practical strategies can significantly enhance your experimental reliability:
- Reduce Variability: Minimize noise in your experimental setup
- Increase Sample Size: Collect more data points when possible
- Focus on Effect Size: Identify meaningful differences that matter to your business
- Use Precise Measurement Tools: Implement accurate tracking mechanisms
Consider statistical power as your experimental quality control. It transforms raw data into actionable insights, helping you make confident marketing decisions. By understanding and applying these principles, you move beyond guesswork to strategic, data driven optimization.
Remember that statistical power is not a one size fits all metric. Each marketing experiment requires a tailored approach that considers your specific goals, resources, and the nuanced dynamics of your target audience. Continuous learning and refinement are key to mastering the art of statistical power in A/B testing.
Below is a checklist table of practical strategies to improve statistical power in A/B tests, allowing marketers to review and implement these actions systematically:
| Strategy | Description | Implemented (Yes/No) |
|---|---|---|
| Increase Sample Size | Gather more data points to boost reliability | |
| Reduce Variability | Minimize external noise and randomness | |
| Enhance Measurement Precision | Use more accurate and consistent tools | |
| Focus on Meaningful Effect Sizes | Target differences that matter for business | |
| Balance Significance Level | Adjust alpha threshold as appropriate |
Common Mistakes and Best Practices for Marketers
Marketing experiments demand precision and strategic thinking. Understanding common pitfalls and implementing best practices can transform statistical power from a complex concept into a reliable decision making tool.
Critical Errors in Statistical Analysis
Research from OARSI Journal reveals that neglecting power analysis before data collection is a fundamental mistake many marketers make. This oversight can render entire experiments ineffective, wasting valuable resources and potentially leading to misguided strategic decisions.
According to Stuart McNaylor's statistical research, misinterpreting non significant results is another critical error. Marketers often mistakenly view non significant findings as proof that no effect exists. In reality, non significance merely indicates insufficient evidence to reject the null hypothesis.
Strategic Best Practices for Robust Experiments
Successful marketing experiments require a methodical approach. Key best practices include:
- Precise Hypothesis Formulation: Define clear, measurable objectives before testing
- Comprehensive Power Calculation: Determine appropriate sample sizes in advance
- Consistent Measurement: Use standardized metrics across experimental variants
- Controlled Environment: Minimize external variables that could skew results
For marketers seeking deeper insights into experimental challenges, explore our comprehensive A/B testing guide to refine your approach.
Avoiding Common Statistical Misconceptions
Understanding statistical nuances prevents costly misinterpretations. Marketers must recognize that statistical significance does not automatically mean practical significance. A statistically significant 0.1% conversion rate improvement might be mathematically interesting but economically irrelevant.
Additionally, context matters tremendously. What works for one audience segment might not translate universally. Continuous testing, careful segmentation, and nuanced interpretation are crucial.
Key principles for maintaining experimental integrity include:
- Transparency: Document all experimental parameters
- Reproducibility: Ensure experiments can be replicated
- Contextual Interpretation: Consider broader business implications
Statistical power is not about achieving perfect results but about making informed decisions with available data. Embrace uncertainty, remain curious, and view each experiment as a learning opportunity.
Remember that great marketing isn't about being right every time it's about systematically reducing uncertainty and making progressively better informed choices. Statistical power provides the framework for this continuous improvement process.
Frequently Asked Questions
What is statistical power in marketing experiments?
Statistical power is the probability of correctly detecting a true effect in an experiment. In marketing, it helps ensure that results are reliable and not just random fluctuations.
Why does statistical power matter for A/B testing?
Statistical power is crucial for A/B testing because it reduces the risk of Type II errors, where a true effect is missed. Adequate statistical power allows marketers to make informed decisions based on robust data.
How is statistical power calculated in marketing studies?
Statistical power is calculated using sample size, effect size, and significance level. By understanding these components, marketers can determine the necessary sample size to detect a meaningful effect in their experiments.
What are common mistakes marketers make related to statistical power?
Common mistakes include neglecting power analysis before experiments, misinterpreting non-significant results as evidence of no effect, and not considering the real-world significance of statistically significant findings.
Unlock Accurate Insights With Faster, More Powerful A/B Testing
Are you tired of running marketing experiments only to realize that poor statistical power left your team guessing instead of growing? The article highlighted how low statistical power leads to missed opportunities, wasted spend, and unreliable results that can send your marketing in the wrong direction. Marketers want experiments they can trust, actionable data, and a truly simple way to make smart, repeatable decisions—without technical hassles.
You do not have to struggle with underpowered tests or clunky tools. Stellar gives you a streamlined A/B testing solution designed specifically for marketers who crave agility, accuracy, and speed. Run statistically sound experiments in minutes using our no-code visual editor and ultra-lightweight script. Deliver personalized experiences with dynamic keyword insertion. Track results in real time to stop guessing and start growing. If you want decision-making backed by reliable data and immediate insights, get started with Stellar’s free plan now and experience the future of optimized marketing. Don’t let low statistical power ruin another test—make your next experiment your most confident one yet.
Recommended
- A/B Testing Significance: 2025 Guide for Marketers & CROs
- AB Testing Challenges Marketers Face: Common Pitfalls in 2025
- Landing Page A/B Testing Strategies for Marketers in 2025
- AB Testing App Strategies for Marketers and Growth Teams 2025
- A/B-test Significantie: De Ultieme Gids voor Marketeers & CRO-specialisten in 2025
- Testing to Optimize Conversions: CRO Strategies for 2025
Published: 7/9/2025