
Web application testing services: Boost CRO with smarter experiments
Running more A/B tests does not automatically make your marketing smarter. In fact, flawed statistical methods and hidden biases can lead you to ship losing variations while celebrating them as wins. Peeking at results early alone can inflate false positives by up to 26%, and running 20 simultaneous tests pushes that risk to 64%. For marketing professionals and product managers at small to medium-sized businesses, those are not abstract numbers. They represent wasted budget, misguided decisions, and missed growth. This guide will help you understand what web application testing services actually offer, which statistical approaches fit your situation, and how to run experiments that produce results you can trust.
Table of Contents
- What are web application testing services?
- Frequentist vs Bayesian: Choosing the right statistical engine
- Avoiding common testing pitfalls: Peeking, power, and multiple comparisons
- Maximizing ROI: Smart setup and actionable metrics for web tests
- Seasonality and real-world variables: Interpreting test outcomes
- Why most web testing fails: Our hard-won lessons for SMB marketers
- Take your web testing to the next level with the right tools
- Frequently asked questions
Key Takeaways
| Point | Details |
|---|---|
| Test setup matters | Choosing the right statistical approach and calculating solid sample sizes is critical for valid results. |
| Avoid common errors | Peeking at tests and running too many comparisons can lead to misleading outcomes that hurt campaign growth. |
| Measure what counts | Defining a clear primary metric and understanding business context gives you actionable, impactful results. |
| External factors matter | Factor in seasonality and real-world events to correctly interpret test results and avoid costly mistakes. |
What are web application testing services?
Web application testing services are platforms and methodologies that let you experiment on your website or app to find out what actually drives user behavior. For marketers and product managers, the most relevant capability is A/B testing, where you split your audience between two versions of a page or element and measure which performs better. But modern services go well beyond simple split tests.
Here is what a well-rounded web application testing service typically includes:
- A/B and multivariate testing: Test one change at a time or multiple variables simultaneously to understand interaction effects.
- User segmentation: Target specific audience groups, such as new visitors, mobile users, or paid traffic, so your results reflect the right people.
- Behavioral experiments: Observe how users navigate, click, and convert to form better hypotheses before running formal tests.
- Performance testing: Measure how page speed and script load times affect conversion rates, not just aesthetics.
- Real-time reporting: Get live data so you can monitor tests without having to wait days for a dashboard refresh.
For marketers focused on conversion rate optimization (CRO), the ability to connect test results directly to revenue metrics is what separates useful platforms from noisy ones. CRO testing strategies that align experiments with specific business goals produce far more actionable data than tests run out of curiosity.
One area that often gets overlooked is the statistical engine powering these services. Statistical methods contrast frequentist and Bayesian approaches, with sequential testing and mSPRT (mixture Sequential Probability Ratio Test) allowing early stopping without inflating error rates. Understanding which engine your platform uses matters more than most marketers realize.
Performance impact is another critical factor. A bloated testing script can slow your site and actually hurt the conversions you are trying to improve. When evaluating web app performance testing tools, always check the script size and how it loads relative to your core content.
Frequentist vs Bayesian: Choosing the right statistical engine
With an understanding of testing features, the next big question is: what statistical model should power your experiments?
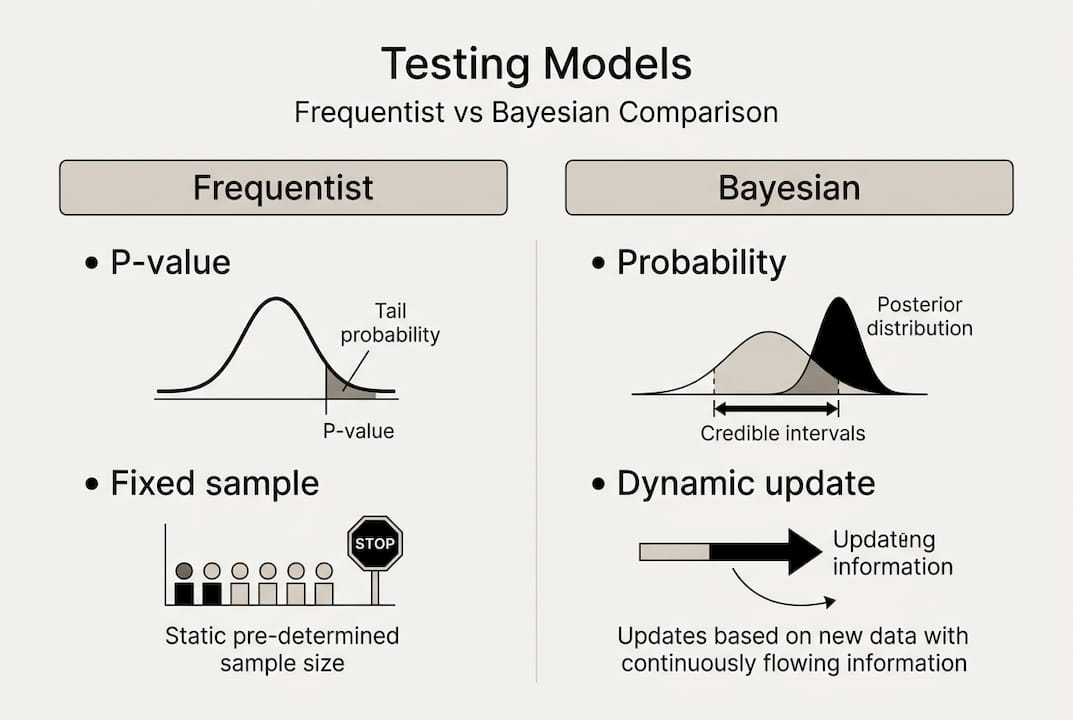
The two dominant approaches are frequentist and Bayesian, and they answer different questions. Frequentist testing asks, "If there were no real difference, how likely is this result?" It uses p-values and confidence intervals, and it requires you to commit to a sample size before you start. Bayesian testing asks, "Given what we have seen, what is the probability that version B is better?" It updates continuously as data comes in.
| Factor | Frequentist | Bayesian |
|---|---|---|
| Core output | P-value, confidence interval | Probability of being best |
| Sample size | Must be pre-defined | Flexible, updates over time |
| Early stopping | Risky without corrections | Safer with proper priors |
| Best for | Compliance, regulated industries | Low-traffic sites, speed |
| Complexity | Lower | Higher (requires prior knowledge) |
Frequentist methods are more conservative for regulated SMBs, while Bayesian engines move faster for low-traffic sites but require you to set reasonable prior assumptions. A bad prior in a Bayesian model can skew your results just as badly as peeking in a frequentist one.
For most small to medium-sized businesses, the practical choice depends on two things: your traffic volume and your tolerance for risk. If you have fewer than 5,000 monthly visitors per variation, Bayesian testing often reaches a usable conclusion faster. If you are running tests that will inform a major product decision or a regulated campaign, frequentist methods give you a defensible, auditable result.
"The best statistical engine is the one your team actually understands and uses correctly. A misapplied Bayesian model is worse than a simple frequentist test done right."
Pro Tip: Before launching any test, decide how often you will check results and stick to that schedule. Checking daily when you planned weekly is still peeking, regardless of which engine you use.
When analyzing test results, always document which statistical method you used and why. This discipline prevents post-hoc rationalization, where teams switch methods after seeing data to get the answer they wanted.
Avoiding common testing pitfalls: Peeking, power, and multiple comparisons
Understanding test methods is only half the story. To get reliable results, you need to sidestep the most frequent mistakes.
The three biggest traps that distort web testing results are peeking, low statistical power, and multiple comparisons. Each one can independently destroy the validity of an otherwise well-designed experiment.
Peeking happens when you check your results before the planned end date and stop the test because it looks like a winner. It feels responsible. It is not. Peeking raises false positives up to 26%, meaning more than one in four "wins" you celebrate could be pure noise. The fix is simple but requires discipline: set your end date before you launch and do not touch the results until then.

Multiple comparisons create a compounding problem. Every additional test you run at the same time increases the probability that at least one result is a false positive by random chance. Running 20 tests simultaneously pushes false positive risk to 64%. That means nearly two out of three significant results could be meaningless.
Here is a quick checklist to protect your tests:
- Define one primary metric before launch, not after.
- Pre-calculate your required sample size using a power calculator.
- Limit simultaneous tests on the same page or audience segment.
- Apply a Bonferroni correction or similar adjustment when running multiple comparisons.
- Never stop a test early based on a "trending" result.
Low statistical power is the quieter killer. Power refers to your test's ability to detect a real difference when one exists. An underpowered test, one with too small a sample, will miss genuine improvements and cause you to incorrectly conclude that a change made no difference. This leads to abandoning ideas that actually work.
For predictive marketing metrics to be useful, the data feeding them needs to be clean. Flawed tests produce flawed inputs. When prioritizing tests, focus on experiments where you have enough traffic to reach statistical power within a reasonable timeframe, typically two to four weeks.
Maximizing ROI: Smart setup and actionable metrics for web tests
Even with the right methodologies and awareness of pitfalls, your outcomes still depend on strategic setup and meaningful measurement.
The most common reason SMB testing programs stall is not a bad tool. It is a missing framework. Teams run tests reactively, without a clear business goal tied to each experiment. Here is a structured approach that consistently produces better ROI:
- Start with a business goal. Not "improve the homepage" but "increase free trial signups by 15% this quarter."
- Form a specific hypothesis. "Changing the CTA button from gray to orange will increase clicks because it creates stronger visual contrast."
- Pre-calculate your sample size. Use your baseline conversion rate and the minimum detectable effect you care about. Always pre-calculate sample size and define your primary metric before you start to avoid p-hacking.
- Run the test to completion. No early stops, no peeking.
- Document and act. Win or lose, record what you learned and feed it into the next hypothesis.
| Test stage | Key action | Common mistake |
|---|---|---|
| Planning | Define primary metric | Picking metrics after seeing data |
| Setup | Calculate sample size | Guessing or using defaults |
| Running | Stick to schedule | Peeking at interim results |
| Analysis | Check for significance | Stopping at "almost significant" |
| Action | Apply learnings | Ignoring losing test insights |
Pro Tip: Treat a losing test as equally valuable as a winning one. A variation that reduced conversions tells you something important about what your audience does not respond to, which is just as useful for validating marketing ideas as a positive result.
Tracking the right conversion metrics means resisting the urge to measure everything. One primary metric, supported by two or three secondary ones, keeps your analysis focused and your decisions clean.
Seasonality and real-world variables: Interpreting test outcomes
With foundational principles set, it is time to tackle the real-world forces that still trip up even experienced marketers.
A test that runs perfectly from a statistical standpoint can still mislead you if external conditions shift during the experiment. Seasonality and distinguishing statistical from practical significance are among the most common edge cases that cause marketers to make wrong calls on otherwise clean data.
Consider a retailer who runs an A/B test on their checkout flow during the two weeks spanning Black Friday. Traffic spikes, buyer intent is unusually high, and the audience skews toward deal-seekers rather than regular customers. Any winning variation from that period may not hold up in January.
Here are the key real-world variables to account for when interpreting results:
- Seasonal demand shifts: Holiday periods, back-to-school cycles, and industry events change user behavior in ways that do not reflect normal patterns.
- Sample ratio mismatch: If one variation receives significantly more traffic than expected, your randomization may be broken. Check this before drawing conclusions.
- Audience composition shifts: A sudden influx of paid traffic or a viral social post can change who is in your test, making results unrepresentative of your core audience.
- Statistical vs practical significance: A result can be statistically significant but too small to matter. A 0.1% lift in conversions may clear the p-value threshold but not justify the engineering cost to implement.
- External events: News cycles, competitor promotions, and platform algorithm changes can all influence user behavior mid-test.
The best practice is to always review test context before acting. Check your traffic sources, audience segments, and any major external events that occurred during the test window. Understanding seasonality in marketing tests is not optional for businesses that see meaningful traffic variation throughout the year.
Why most web testing fails: Our hard-won lessons for SMB marketers
As you refine your approach based on the guidance above, here is the reality we have learned from working with dozens of SMB marketing teams: most testing programs fail not because of bad tools but because of bad habits.
The biggest misconception is that A/B testing is a shortcut. Teams run a test, see a 10% lift, ship the winner, and expect compounding growth. But without a disciplined process, that lift often evaporates or was never real to begin with.
What actually drives sustainable improvement is a culture of structured learning. That means writing down your hypothesis before you test, sharing results across your team whether they win or lose, and building a backlog of experiments grounded in real user behavior rather than gut instinct.
We have also seen teams get obsessed with statistical significance while ignoring whether the change actually matters to the business. A 2% improvement in button click rate is not worth celebrating if it does not move revenue. Focus on metrics that connect directly to growth.
Finally, alignment matters more than most guides admit. When marketing, product, and engineering are not on the same page about what a test is trying to prove, results get cherry-picked and decisions get made for the wrong reasons. Smarter testing for SaaS teams starts with shared goals, not shared dashboards.
Take your web testing to the next level with the right tools
Ready to turn your insights into real impact? The principles in this guide only pay off when your testing platform can keep up with your ambitions.
Stellar is built specifically for marketers and product managers at small to medium-sized businesses who want rigorous, reliable testing without needing a data science team. With a no-code visual editor, a 5.4KB script that keeps your site fast, real-time analytics, and advanced goal tracking, Stellar makes it easy to run experiments that actually inform decisions. There is a free plan for sites with under 25,000 monthly tracked users, so you can start building your testing discipline today without a budget commitment. Smarter experiments are closer than you think.
Frequently asked questions
What is the difference between frequentist and Bayesian A/B test engines?
Frequentist engines use traditional p-values and are more conservative, while Bayesian engines interpret probability and often let you make decisions faster, especially with smaller audiences. Statistical methods contrast frequentist vs Bayesian approaches in meaningful ways depending on your traffic volume and risk tolerance.
How does peeking at test results early affect outcomes?
Checking results before your planned end date, known as peeking, can falsely signal a win and inflate your chance of error. Peeking can cause up to 26% more false positives, meaning you may ship a losing variation thinking it won.
Why is pre-calculating sample size important in web tests?
Calculating the right sample size in advance ensures your test findings are statistically valid and not the result of random chance. Always pre-calculate sample size and define your primary metric before launch to avoid p-hacking.
How do seasonality and external factors affect A/B testing results?
Seasonal trends and outside events can shift your audience composition and behavior mid-test, making results unrepresentative of normal conditions. Seasonality and distinguishing statistical vs practical significance are edge cases that require you to always interpret data within its broader business context.
Recommended
Published: 4/2/2026